
Обучение системы при малом размере обучающей выборки
| Входные данные: | Система анализа речи со следующими стартовыми параметрами:
+Конфигурация нейросети Число входов: 20 Нейронов во входном слое: 10 Нейронов в символьном слое: 5 Эффекторов: 4 +Эффекторы +EF0 Тип: Частота форманты Индекс: 1 Min: 100.0000 Max: 3000.0000 +EF1 Тип: Воздействие форманты Индекс: 1 Min: 0.0000 Max: 0.8000 +EF2 Тип: Частота форманты Индекс: 2 Min: 1000.0000 Max: 4000.0000 +EF3 Тип: Воздействие форманты Индекс: 2 Min: 0.0000 Max: 0.1000 +Скорости обучения alpha0: 0.1000 alpha1: 1.0000 alpha2: 0.0500 alpha3: 0.5000 +Модель синтеза Частота основного тона: 115 Частота шума: 5000.0000 Четкость шума: 0.0500 Число формант: 3 +Форманты +F0 Частота: 100.0000 Четкость: 0.1000 Воздействие: 1.0000 +F1 Частота: 259.7322 Четкость: 0.5000 Воздействие: 0.1362 +F2 Частота: 1824.6669 Четкость: 0.1000 Воздействие: 0.0264 +Алфавит S0='а' S1='и' S2='о' S3='у' S4='?' Обучающая выборка: звуковые файлы с записанными звуками а,и,о,у и соответствующие текстовые файлы. |
| Цель эксперимента: | 1.Анализ процесса обучения при небольшой обучающей выборке, элементы которой близки друг к другу
2.Обучение синтезу сложного сигнала с использованием 4 эффекторов |
| Ход эксперимента: | Как и в предыдущем эксперименте, обучение проводилось в три этапа, перед каждым этапом корректировались значения скоростей обучения. |
| Результат: | Система со 100% результатом распознает тестовые примеры и звуки, произносимые в микрофон. Получены удовлетворительные результаты при обучении синтезу: полученное распределение формант для каждого звука соответствует распределению формант в оригиналах, но уровни (воздействия) формант в некоторых звуках различаются. Предполагается, что это происходит из-за несовпадения огибающих этих формант.
Результат обучения синтезу 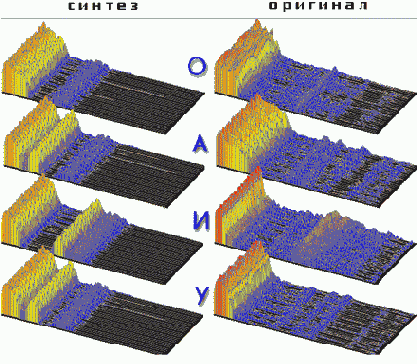 Рис. 19 |
| Выводы: | Система хорошо обучается распознаванию, даже если входные сигналы достаточно близки друг другу.
Обучение синтезу длилось дольше, чем в предыдущем эксперименте с одним эффектором – увеличение числа эффекторов существенно снижает эффективность механизма стохастического обучения. Введенные в модель синтеза упрощения (3 форманты и 4 переменных параметра) не позволяют получить качественный синтез. Следовательно, необходимо увеличивать число управляющих параметров, участвующих в синтезе и более точно задавать форму огибающей формант. |